HighlightBench: Benchmarking Markup-Driven Table Reasoning in Scientific Documents
Abstract
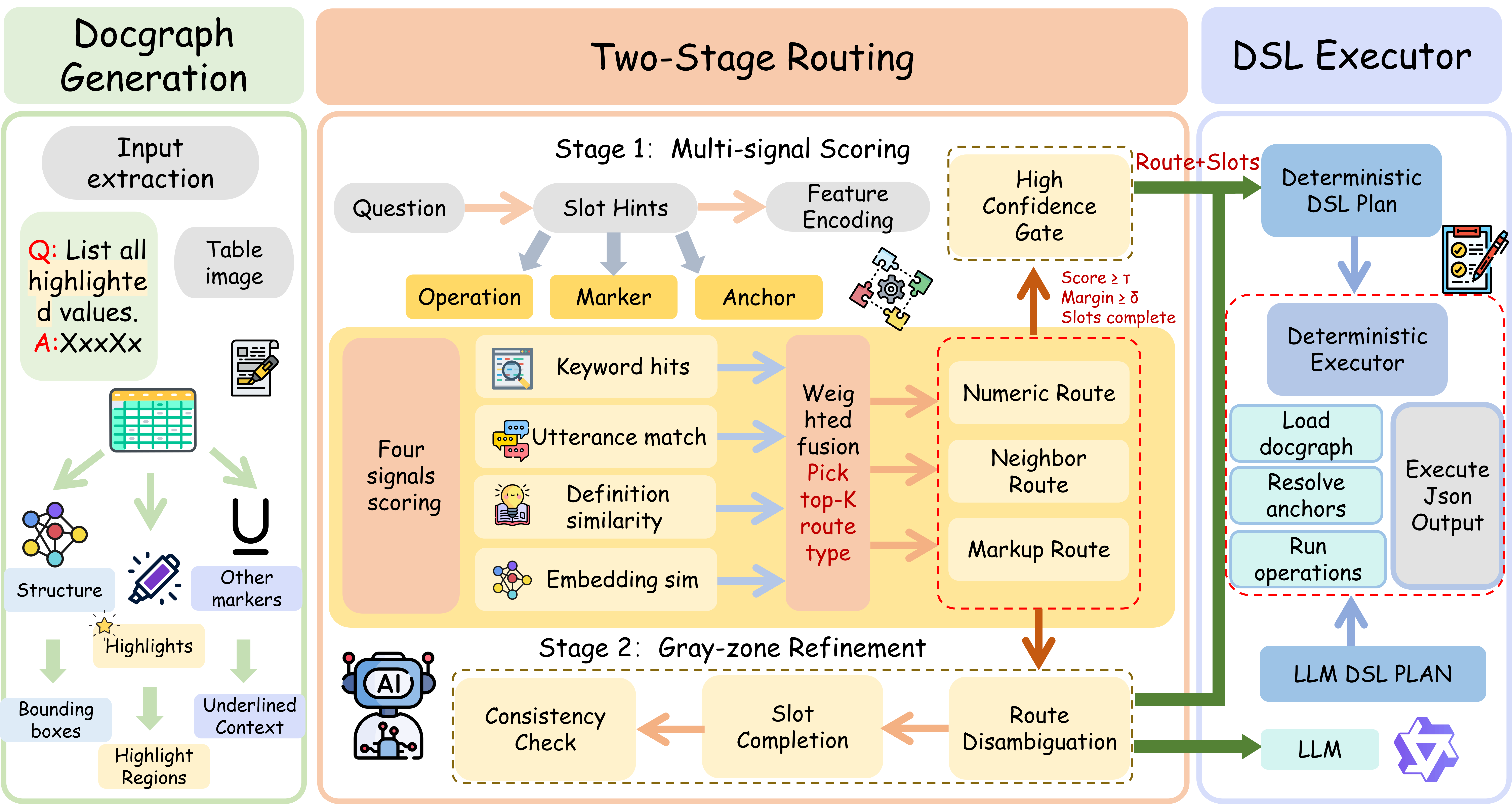
Visual markups such as highlights, underlines, and bold text are common in table-centric documents. Although multimodal large language models (MLLMs) have made substantial progress in document understanding, their ability to treat such cues as explicit logical directives remains under-explored. More importantly, existing evaluations cannot distinguish whether a model fails to see the markup or fails to reason with it. This creates a key blind spot in assessing markup-conditioned behavior over tables. To address this gap, we introduce HighlightBench, a diagnostic benchmark for markup-driven table understanding that decomposes evaluation into five task families: Markup Grounding, Constrained Retrieval, Local Relations, Aggregation & Comparison, and Consistency & Missingness. We further provide a reference pipeline that makes intermediate decisions explicit, enabling reproducible baselines and finer-grained attribution of errors along the perception-to-execution chain. Experiments show that even strong models remain unstable when visual cues must be consistently aligned with symbolic reasoning under structured output constraints.
Figures